An illustrative example of a full end-to-end detoxai use case
[ ]:
# !pip install detoxai
[ ]:
import torch.nn as nn
import torchvision
import lightning as L
import pandas as pd
# DetoxAI
import detoxai
from detoxai.utils.datasets import get_detoxai_datasets, DetoxaiDataset
from detoxai.utils.transformations import SquarePad
from detoxai.utils.dataloader import DetoxaiDataLoader
from detoxai.core.model_wrappers import FairnessLightningWrapper
from detoxai.visualization import ScatterVisualizer, SSVisualizer
from detoxai import download_datasets, CorrectionResult
L.seed_everything(123, workers=True)
device = "cpu"
print(f"Using DetoxAI version: {detoxai.__version__}")
Seed set to 123
'0.3.3'
Let’s start from fine-tuning a pretrained ResNet on a CelebA dataset
Step 1: Download CelebA dataset
We have a utility function for downloading celeba and fairface datasets and then another utility function to parse the dataset. Feel free to use them or download the dataset manually and parse it yourself.
[2]:
download_datasets(["celeba"])
CELEBA_DATASET_CONFIG = {
"name": "celeba",
"target": "Smiling", # target attribute that should be predicted
# Note that celeba has quite a lot of examples, so to make things easier,
# we will use a smaller subset of the dataset
"splits": {"train": 0.003, "test": 0.01, "unlearn": 0.003, "no": 0.984},
}
datasets: list[DetoxaiDataset] = get_detoxai_datasets(
CELEBA_DATASET_CONFIG,
transform=torchvision.transforms.Compose(
[SquarePad(), torchvision.transforms.ToTensor()]
),
device=device,
)
Step 2: Setup the dataset and dataloaders
Dataloader has to output tuples of (image, label, protected attribute)
[ ]:
pa = "Wearing_Hat" # protected attribute
pa_value = 1 # protected attribute value
num_classes = datasets["train"].get_num_classes()
collate_fn = datasets["train"].get_collate_fn(pa, pa_value)
dataloader_train = DetoxaiDataLoader(
datasets["train"], collate_fn=collate_fn, batch_size=256
)
dataloader_unlearn = DetoxaiDataLoader(
datasets["unlearn"], collate_fn=collate_fn, batch_size=128
)
dataloader_test = DetoxaiDataLoader(
datasets["test"], collate_fn=collate_fn, batch_size=256
)
Step 3: Define the model
DetoxAI supports binary classification and binary protected attributes
[4]:
model = torchvision.models.resnet18(
weights=torchvision.models.ResNet18_Weights.IMAGENET1K_V1
)
model.fc = nn.Linear(model.fc.in_features, 2) # Make it binary classification
model = model.to(device)
Step 4: Fine-tune the model on the CelebA dataset
We use our FairnessLightningWrapper, but you can also use the standard PyTorch Lightning module or any other training framework. The only thing you have to keep in mind is adapting your training procedure to handle the protected attribute. If you don’t know how to do that, go ahead and check out our FairnessLightningWrapper. It should be fairly simple to understand.
[5]:
trainer = L.Trainer(
logger=False,
max_epochs=3,
devices=[int(str(device).split(":")[1])] if str(device) != "cpu" else 1,
accelerator="gpu" if "cuda" in device else "cpu",
enable_checkpointing=False,
)
trainer.fit(FairnessLightningWrapper(model), dataloader_train)
/home/inf148179/detoxai/detoxai/.venv/lib/python3.11/site-packages/lightning/fabric/plugins/environments/slurm.py:204: The `srun` command is available on your system but is not used. HINT: If your intention is to run Lightning on SLURM, prepend your python command with `srun` like so: srun python /home/inf148179/detoxai/detoxai/.venv/lib/python3.11 ...
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
/home/inf148179/detoxai/detoxai/.venv/lib/python3.11/site-packages/lightning/pytorch/utilities/parsing.py:208: Attribute 'model' is an instance of `nn.Module` and is already saved during checkpointing. It is recommended to ignore them using `self.save_hyperparameters(ignore=['model'])`.
/home/inf148179/detoxai/detoxai/.venv/lib/python3.11/site-packages/lightning/pytorch/utilities/parsing.py:208: Attribute 'criterion' is an instance of `nn.Module` and is already saved during checkpointing. It is recommended to ignore them using `self.save_hyperparameters(ignore=['criterion'])`.
| Name | Type | Params | Mode
-------------------------------------------------------
0 | model | ResNet | 11.2 M | train
1 | criterion | CrossEntropyLoss | 0 | train
-------------------------------------------------------
11.2 M Trainable params
0 Non-trainable params
11.2 M Total params
44.710 Total estimated model params size (MB)
69 Modules in train mode
0 Modules in eval mode
/home/inf148179/detoxai/detoxai/.venv/lib/python3.11/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:424: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=95` in the `DataLoader` to improve performance.
Epoch 0: 0%| | 0/3 [00:00<?, ?it/s]
/home/inf148179/detoxai/detoxai/.venv/lib/python3.11/site-packages/lightning/pytorch/core/module.py:758: `training_step` must be implemented to be used with the Lightning Trainer
Epoch 2: 100%|██████████| 3/3 [00:08<00:00, 0.36it/s]
`Trainer.fit` stopped: `max_epochs=3` reached.
Epoch 2: 100%|██████████| 3/3 [00:08<00:00, 0.36it/s]
Step 5: After fine-tuning, visualize saliency maps to see the “before”
The first type of visualization are aggregated images and saliency maps side-by-side. They show the average image and saliency map for each class and protected attribute combination.
[6]:
visualizer = SSVisualizer(dataloader_train, model)
visualizer.visualize_agg(0)

[7]:
visualizer.visualize_batch(batch_num=0, max_images=16)

Step 6: Debiasing with DetoxAI
First, check the available debiasing methods
[8]:
detoxai.get_supported_methods()
[8]:
['SAVANIRP',
'SAVANILWO',
'SAVANIAFT',
'ZHANGM',
'RRCLARC',
'PCLARC',
'ACLARC',
'LEACE',
'ROC',
'NT',
'FINETUNE']
Then start the debiasing process through .debias().
This will take a while, because many of the methods are computationally expensive as they fine-tune the model in their own way.
While DetoxAI works with CPU, you definitely want to run this on GPU to significantly speed up the computations.
[9]:
# this will run all the debiasing methods,
# you can pass which ones you want to run by passing methods=["RRCLARC", "SAVANIAFT", ...]
results: dict[str, CorrectionResult] = detoxai.debias(
model,
dataloader_unlearn,
test_dataloader=dataloader_test, # This is optional, but we can use it to evaluate the model and have metrics in the results
methods=[
"RRCLARC",
"ACLARC",
"LEACE",
"ZHANGM",
"SAVANIAFT",
"NT",
], # Here, we run only a select few methods
return_type="all", # this will return all the results, you can also use "pareto-front" or "best"
)
/home/inf148179/detoxai/detoxai/.venv/lib/python3.11/site-packages/lightning/pytorch/utilities/parsing.py:208: Attribute 'model' is an instance of `nn.Module` and is already saved during checkpointing. It is recommended to ignore them using `self.save_hyperparameters(ignore=['model'])`.
/home/inf148179/detoxai/detoxai/.venv/lib/python3.11/site-packages/lightning/pytorch/utilities/parsing.py:208: Attribute 'criterion' is an instance of `nn.Module` and is already saved during checkpointing. It is recommended to ignore them using `self.save_hyperparameters(ignore=['criterion'])`.
/home/inf148179/detoxai/detoxai/.venv/lib/python3.11/site-packages/lightning/pytorch/utilities/parsing.py:208: Attribute 'performance_metrics' is an instance of `nn.Module` and is already saved during checkpointing. It is recommended to ignore them using `self.save_hyperparameters(ignore=['performance_metrics'])`.
/home/inf148179/detoxai/detoxai/.venv/lib/python3.11/site-packages/lightning/pytorch/utilities/parsing.py:208: Attribute 'fairness_metrics' is an instance of `nn.Module` and is already saved during checkpointing. It is recommended to ignore them using `self.save_hyperparameters(ignore=['fairness_metrics'])`.
Extracting Activations: 100%|██████████| 5/5 [00:05<00:00, 1.09s/it]
/home/inf148179/detoxai/detoxai/.venv/lib/python3.11/site-packages/lightning/fabric/plugins/environments/slurm.py:204: The `srun` command is available on your system but is not used. HINT: If your intention is to run Lightning on SLURM, prepend your python command with `srun` like so: srun python /home/inf148179/detoxai/detoxai/.venv/lib/python3.11 ...
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
/home/inf148179/detoxai/detoxai/.venv/lib/python3.11/site-packages/lightning/pytorch/utilities/parsing.py:44: Attribute 'model' removed from hparams because it cannot be pickled. You can suppress this warning by setting `self.save_hyperparameters(ignore=['model'])`.
/home/inf148179/detoxai/detoxai/.venv/lib/python3.11/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:424: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=95` in the `DataLoader` to improve performance.
`Trainer.fit` stopped: `max_epochs=1` reached.
GPU available: False, used: False
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
/home/inf148179/detoxai/detoxai/.venv/lib/python3.11/site-packages/lightning/pytorch/core/module.py:758: `training_step` must be implemented to be used with the Lightning Trainer
`Trainer.fit` stopped: `max_epochs=1` reached.
Zhang: Adversarial Fine Tuning: 17%|█▋ | 1/6 [00:04<00:20, 4.13s/it]/home/inf148179/detoxai/detoxai/src/detoxai/methods/savani/zhang.py:199: UserWarning: The use of `x.T` on tensors of dimension other than 2 to reverse their shape is deprecated and it will throw an error in a future release. Consider `x.mT` to transpose batches of matrices or `x.permute(*torch.arange(x.ndim - 1, -1, -1))` to reverse the dimensions of a tensor. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:3683.)
m_grad_proj = (m_grad.T @ c_grad) * c_grad
Zhang: Adversarial Fine Tuning: 100%|██████████| 6/6 [03:46<00:00, 37.80s/it]
Savani: Adversarial Fine Tuning: 100%|██████████| 10/10 [01:58<00:00, 11.83s/it]
Let’s see what we have in the end.
[10]:
results
[10]:
{'RRCLARC': Results for: RRCLARC,
'ACLARC': Results for: ACLARC,
'LEACE': Results for: LEACE,
'ZHANGM': Results for: ZHANGM,
'SAVANIAFT': Results for: SAVANIAFT,
'NT': Results for: NT,
'Vanilla': Results for: Vanilla}
[17]:
debiased_model = results["SAVANIAFT"].get_model()
Visualize the saliency maps again to see the “after” for RRCLARC.
[18]:
visualizer2 = SSVisualizer(dataloader_train, debiased_model)
visualizer2.visualize_agg(0)

[19]:
visualizer2.visualize_batch(batch_num=0, max_images=16)

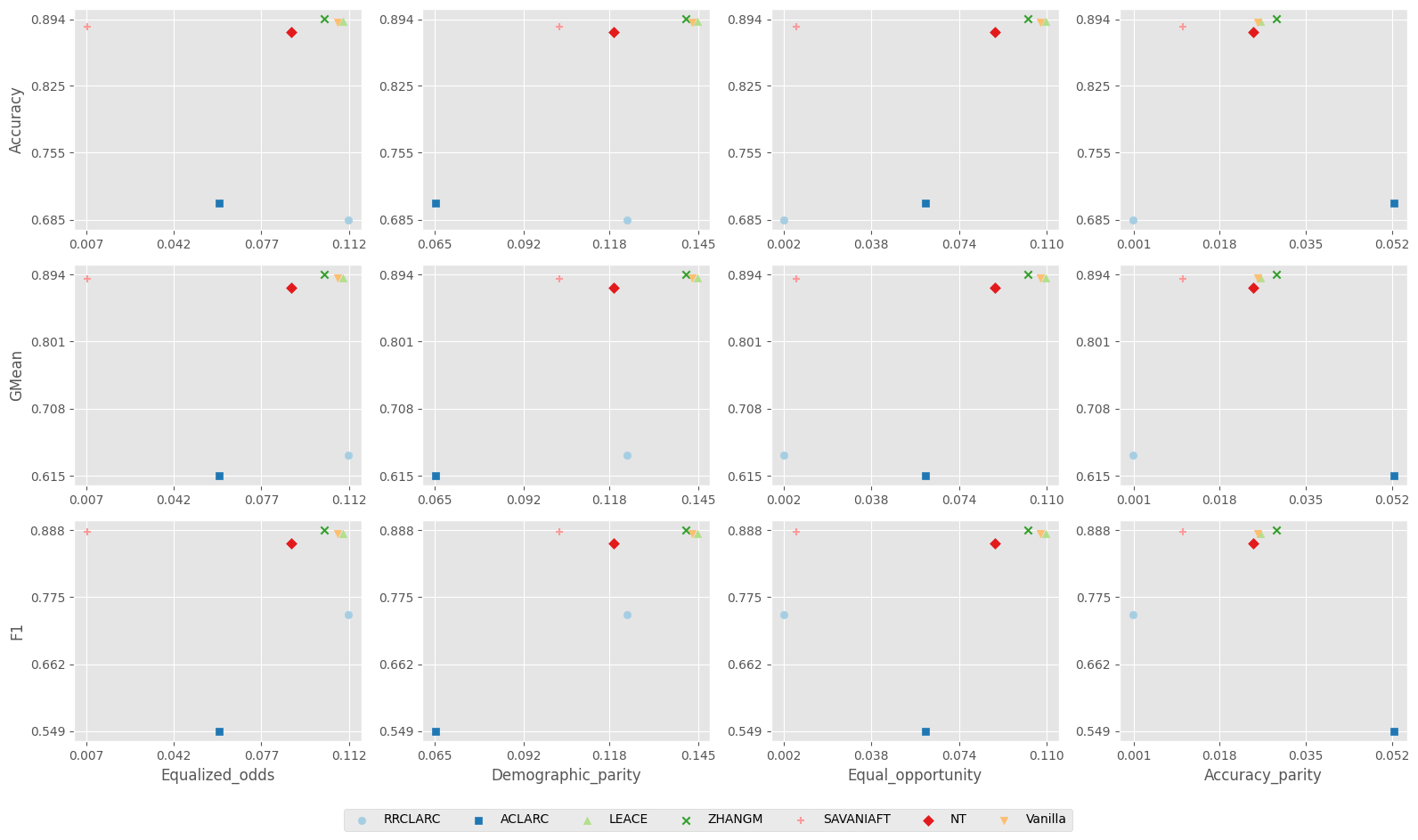
We can also see all the methods and their final fairness vs performance trade-off on a scatter plot
[ ]:
scatter_vis = ScatterVisualizer()
scatter_vis.create_plot(results)
[ ]: